|
ORBEL, the Belgian O.R. Society (Sogesci-B.V.W.B.) organised a
one-day symposium on the
Interface between Data Mining and Operations Research
on Wednesday 16 March 2005 at the
Facultés Universitaires Saint-Louis (FUSL) in Brussels
The symposium is now over !
Many thanks to the organisers, the seven speakers and everybody who attended.
The slides for the presentations and a list of participants are now available for download !
Schedule
| 08.30 - 09.00 | Registration |
| 09.00 - 09.10 | Welcome address |
| 09.10 - 09.55 | Toon Calders (UA),
Frequent pattern mining, abstract, slides |
| 10.00 - 10.45 | Gianluca Bontempi (ULB),
Feature selection methods for mining bio-informatics data, abstract, slides |
| 10.50 - 11.35 | Koen Vanhoof (LUC),
A framework to improve product assortment decisions, abstract, slides |
| 11.40 - 12.25 | Emilio Carrizosa (Universidad de Sevilla, Spain),
Arbitrary-norm support vector machine. Properties and Applications, abstract, slides |
| 12.30 - 13.45 | Lunch |
| 14.00 - 14.45 | Luc De Raedt (Universität Freiburg, Germany),
Constraint-based data mining and inductive databases with an application in molecular feature mining, abstract, slides |
| 14.50 - 15.35 | Louis Wehenkel (ULg),
Decision and regression tree ensemble methods and their application in automatic learning, abstract, slides |
| 15.40 - 16.25 | Marco Saerens (UCL),
The principal components analysis of a graph:
Application to a collaborative recommendation task, abstract, slides |
Location: The symposium will be held at the Facultés Universitaires
Saint-Louis (FUSL), 43 Boulevard du Jardin Botanique, B-1000 Brussels, located close to the Brussels North railway station ; see the following access map. The symposium will take place in the Salle des Examens.
Registration: Registration in advance is required. Please fill in the following registration form and sent it as an attachment of an email to the symposium organiser Gerrit Janssens at [email protected].
Subscription fees: 30 Euro for members of the Sogesci-BVWB or for students; 50 Euro for non-members non-students. The fees have to be paid on the account from the KBC with number 403-4055261-55 with the message DMOR + participant name, or on location. An invoice will be sent on request by e-mail to Gerrit Janssens at [email protected]. The subscription fee includes participation to the conference, documentation material on the talks on paper, coffee or soft drinks and a lunch.
Further questions should be addressed to the symposium organiser Gerrit Janssens at [email protected].
Abstracts
- Toon Calders (UA), Frequent pattern mining
(download the slides of the presentation)
In recent years, mining frequent itemsets has been one of the most
active research areas in data mining. In my talk I will give a (biased)
overview of the research in this area. The survey will include:
depth-first versus breadth-first algorithms, mining with constraints,
mining maximal frequent itemsets, closed sets, and mining more complex
data types and patterns. Throughout the talk, the focus will be on
motivating the different research directions and providing intuition for
the proposed solutions and algorithms, rather than on technical details.
- Gianluca Bontempi (ULB), Feature selection methods for mining bio-informatics data
(download the slides of the presentation)
The use of data mining techniques in bioinformatics is continuously
confronted with the problem of managing datasets where the number of features is
much larger than the number of samples (high feature-to-sample ratio datasets). The talk
will first discuss some examples (from inference of regulatory networks to discrimination
in cancer classification) and then will focus on some issues to be be taken into account for effectively dealing with this type of data.
- Koen Vanhoof (LUC), A framework to improve product assortment decisions
(download the slides of the presentation)
It has been claimed that the discovery of association rules is well suited
for applications of market basket analysis to reveal regularities in the
purchase behaviour of customers. However today, one disadvantage of
associations discovery is that there is no provision for taking into account
the business value of an association. Therefore, recent work indicates that
the discovery of interesting rules can in fact best be addressed within a
microeconomic framework. This study integrates the discovery of frequent
itemsets with a (microeconomic) model for product selection (PROFSET). The
model enables the integration of both quantitative and qualitative (domain
knowledge) criteria. Sales transaction data from a fully automated
convenience store are used to demonstrate the effectiveness of the model
against a heuristic for product selection based on product-specific
profitability. We show that with the use of frequent itemsets we are able to
identify the cross-sales potential of product items and use this information
for better product selection. Furthermore, we demonstrate that the impact of
product assortment decisions on overall assortment profitability can easily
be evaluated by means of sensitivity analysis.
- Emilio Carrizosa (Universidad de Sevilla, Spain), Arbitrary-norm support vector machine. Properties and Applications
(download the slides of the presentation)
In this talk we will explore the optimization problems found in Support Vector
Machines (SVM) when distances are measured via arbitrary (not necessarily
Euclidean) norms. Particular attention will be given to the polyhedral case,
since the optimization problems obtained are transformed into Linear Problems,
thus solvable via standard LP optimizers.
The application of the SVM paradigm to the construction of an interactive
multicriteria algorithm will be also discussed.
- Luc De Raedt (Universität Freiburg, Germany) Constraint-based data mining and inductive databases with an application in molecular feature mining
(download the slides of the presentation)
Constraint based mining and inductive databases are a recent research
stream within data mining.
It aims at supporting the knowledge discovery process by means of
declarative inductive queries,
which are used for querying for patterns. Various types of constraints
(and corresponding solvers)
will be introduced. A case study in the field of molecular feature
mining will be presented in the
system MolFea.
This talk will be based on
De Raedt, L. A perspective on inductive databases, SIGKDD Explorations,
4(2), 2002 and related papers.
- Louis Wehenkel (ULg), Decision and regression tree ensemble methods and their application in automatic learning
(download the slides of the presentation)
The talk presents a new supervised learning algorithm called Extra-Trees
(extremely randomized trees), which builds ensembles of decision or regression
trees by randomizing the choice of attribute and cut-point. After the discussion
of the main properties of this method, we present three different applications:
tree-based batch mode reinforcement learning; pixel-based image classification,
and biomarker identification in proteomics.
- Marco Saerens (UCL), The principal components analysis of a graph:
Application to a collaborative recommendation task
(download the slides of the presentation)
This work presents some general procedures for
computing dissimilarities/similarities between
elements of a database or, more generally, nodes
of a weighted, undirected, graph. It is based on
a Markov-chain model of random walk through the
database. The model assigns transition
probabilities to the links between elements, so
that a random walker can jump from element to
element. Unlike the standard "shortest path"
distance, these quantities, representing
similarities between any two elements, have the
nice property of decreasing (increasing) when the
number of paths connecting these two elements
increases and when the "length" of any path
decreases.
We also define the principal component analysis
(PCA) of a graph as the subspace projection that
preserves as much variance as possible, in terms
of the defined quantity. This PCA has some
interesting links with spectral graph theory, in
particular "spectral clustering".
The model is applied on a collaborative
recommendation task where suggestions are made
about which movies people should watch based upon
what they watched in the past. Experimental
results on the MovieLens database show that the
Laplacian pseudoinverse-based similarity
outperforms the other methods.
List of participants:
contact information (address, email) for each participant is available in the following PDF list.
- BONTEMPI Gianluca, Département d'Informatique, Machine Learning Group, Université Libre de Bruxelles
- CALDERS Toon, Dept. Wiskunde-Informatica, Universiteit Antwerpen
- CARRIZOSA Emilio, Faculdad de Matematicas, Universidad de Sevilla
- CRANINX Michel, Universiteit Gent
- CURVERS Daan, Universiteit Gent
- DE BAETS Bernard, Department of Applied Mathematics, Biometrics and Process Control, Universiteit Gent
- DE BRUYNE Steven, Vakgroep Wiskunde, Operationeel Onderzoek, Statistiek en Informatica, Vrije Universiteit Brussel
- DE RAEDT Luc, Institut für Informatik, Universität Freiburg
- DE VOS Daniella, Industrial Management, Universiteit Gent
- DE WEIRDT Marjolein, Universiteit Gent
- GEURTS Pierre, Institut Montefiore, Université de Liège
- GLINEUR François, Center for Operations Research and Econometrics, Université Catholique de Louvain
- JANSSENS Gerrit, Departement Bedrijfskunde, Limburgs Universitair Centrum
- JANSSENS Saskia, Department of Applied Mathematics, Biometrics and Process Control, Universiteit Gent
- LAVENDHOMME Thierry, Facultés Universitaires Saint-Louis
- LOOMAN Brecht, Universiteit Gent
- LOUTE Etienne, Facultés Universitaires Saint-Louis
- MAREE Raphael, Institut Montefiore, Université de Liège
- NOWE Ann, Vakgroep Informatica en Toegepaste Informatica, Vrije Universiteit Brussel
- PASTOR Franck, Facultés Universitaires Saint-Louis
- PLASTRIA Frank, Vakgroep Wiskunde, Operationeel Onderzoek, Statistiek en Informatica, Vrije Universiteit Brussel
- ROOSE Frederik, Universiteit Gent
- SAERENS Marco, School of Management (IAG), Université Catholique de Louvain
- SAVEYN Pieter, Universiteit Gent
- VANHAVERBEKE Lieselot, Vakgroep Wiskunde, Operationeel Onderzoek, Statistiek en Informatica, Vrije Universiteit Brussel
- VANHOOF Koen, Departement Bedrijfskunde, Limburg Universitair Centrum
- VERTOMMEN Joris, Centrum voor Industrieel Beleid, Katholieke Universiteit Leuven
- WEHENKEL Louis, Institut Montefiore, Université de Liège
Access map
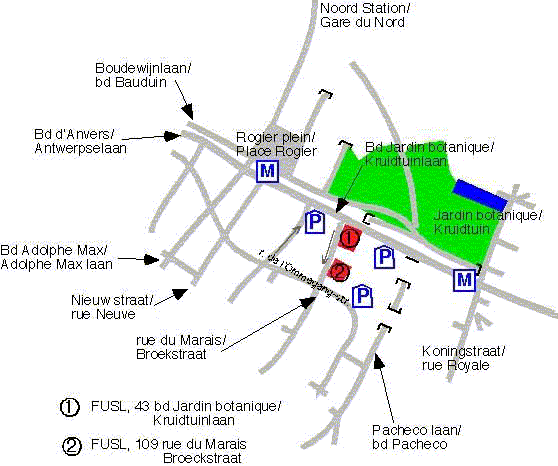
The symposium will take place in building number 1 on the map, in the exam room (Salles des examens), on the second floor. There will signs leading to it: after entrance, go through the next door in front of you. Then take the lift on your right, just after the main secretariat door. Exit the lift at the second floor (according to European floor metric!) on your left. The room is the exam room with a double door, just in front of you.
|
